HBase思维脑图
hbase & hdfs
- hdfs只支持顺序读取和追加数据
- hbase可以顺序的查找,增量更新已有数据(hbase是建立在hdfs之上,所以不支持修改(可以进行删除),对于修改内容,通过用时间戳进行控制)
列存储
-
数据按列存储
-
数据就是索引
-
只访问查询所涉及的列
-
并发处理:可以使用线程A查询col1列的数据,线程B查询col2列的数据
-
高效压缩:因为每一列的数据高度相似,所以压缩比特别高
hbase特点
- 大:一个表可以有上亿行和上百万列
- 面向列:面向列的存储和权限控制,检索,可以动态增加列
- 稀疏:对于空列不占用存储空间
- 多个数据版本,每个单元的数据可以有多个版本,版本号默认是插入的时间戳
- 唯一数据类型:所有数据类型都是二进制字节
jion问题
物理模型
- 每个立足存储在hdfs上的一个单独的文件中
- key和版本号在每个列族中都会保存一份
- 单元内的空值不会存储
- 默认返回版本号最大的一列
物理存储
- rowkey按照字典序排序
- 每个table会在行的方向上分割为多个region,默认为一个region当数据量达到阈值时会进行分割
- region是分布式存储的最小单元
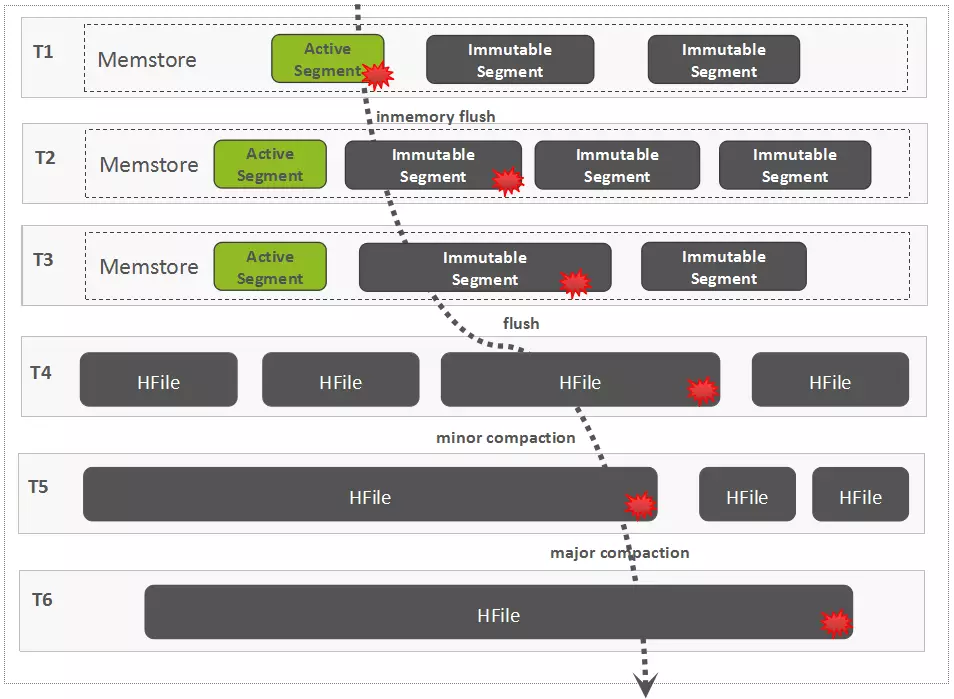
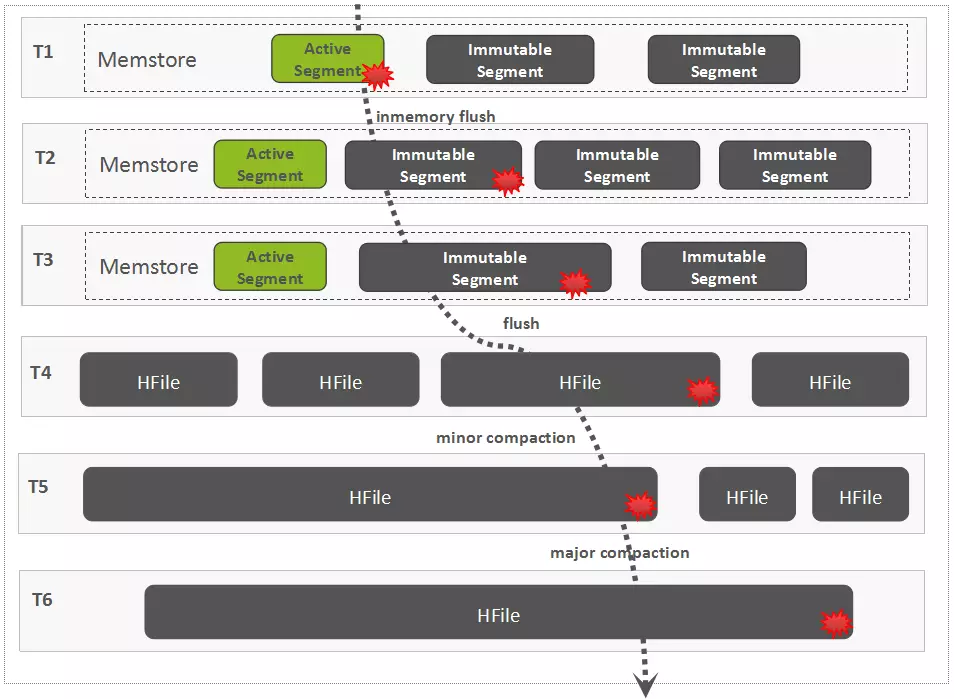
- 一个region是由多个sotre组成,每个store保存一个列族
- 每个store由分为memSotre和sotreFile,memSotre保存在内存中,sotreFile保存在Hdfs上
Hlog
容错
master容错
master由Zookeeper进行选举
影响:region无法进行切分,负载均衡等无法进行,但不影响读操作
RegionSerer容错
regionServer定时向zookeeper发送心跳,如果zookeeper没有收到心跳则通知Master将重新分配region(坏掉的region上的数据怎么办)
Zookeeper容错
访问方式
- java Api
- shell
- Thrift 利用thrift序列化技术,支持C,PHP等不同语言进行访问
- Restfull 支持rest风格的访问
- mapreduce
- 在hbase3.0里面提供了spark访问的支持
region定位
hbase优化
- 预分区:
- rowkey的设计:
- 尽量将一起读的数据存储到一个块。
- rowkey最大不能超过64kb
- key按照字典序排列
- 不要在一张表里面定义太多的column family
- in memory: 通过HColumnDescriptor.setInMemory(true)将表放到RegionServer的缓存中,提高RegionServer的命中率
- max version: 设置最大版本号,例如:如果只需要保存最新版本数据,可以设置setMaxVersion(1);
- time to live: 设置数据的生命周期
- 缓存设置原则:在最靠近客户端设置缓存。
- Compact & split: 合并和分区
- major compact: 将所有的store file合并成一个
- minor compact:
- 多htable并发写、批量写
- htable参数设置:
- auto flush : 自动刷新,将客户端数据一次性提交到服务器,而不是一条一条的put
- write buffer: 写缓冲区大小
- 缓存查询结果
- HTable和HTablePool
- HTable对象不是线程安全的
Hbase shell
- 创建表可以只创建列族
- 删除列族前需要先禁用表
- 插入数据:
put 'tableName','rowKey','Familay:col','val' - 查看:
get 'tableName','rowKey','Familay:col'
启动shell脚本访问> hbase shell查询帮助> help查看服务器状态>status查看版本号>version创建表:> create 'member','member_id','address','info'查看所有表:> list查看表状态> describe 'member'删除列族> disable 'member'>alter 'member',{NAME=>'member_id',METHOD=>'delete'}>enable 'member'删除列> delete 'member','djt','info:age'统计表总行数> count 'member'清空表> truncate 'member' 查看表是否存在> exist 'member'判断表是否可用>is_enabled 'member'查看表是否不可用>is_disabled 'member'删除表> disable 'member'> drop 'member'插入数据> put tableName,rowKey,Familay:col,val> put 'member','djt','info:age','28'> put 'member','djt','info:birthday','1992-09-09'> put 'member','djt','address:country','china'> put 'member','djt','address:city','beijing'查看全表信息> scan根据rowKey查询> get 'member','djt'获取列族> get 'member','djt','info'获取具体列> get 'member','djt','info:age'更新(覆盖)>put 'member','djt','info:age','30'HBaseAdmin hbaseAdmin=new HbaseAdmin(confg);hbaseAdmin.createTable(tabDesc);HTable table=new HTable(conf,tabName);Put put1=new Put(getBytes(djt));put1.add(getBytes("address"),getBytes("country"),getBytes("china"));table.put(put1);Get get=new Get(getBytes("djt"));Result r=table.get(get);Scan scan=new Scan();scan.addColumn(getBytes("info",getBytes("company")));ResultScanner scanner=table.getScanner(scan);Delete del=new Delete(getBytes("djt"));del.deleteColum(getBytes("info"),getBytes("age"));table.delete(del);table.close(); Protocol Buffer
轻便高效的结构化数据存储格式。可以对结构化的数据进行序列化。可用于通讯协议,数据存储等领域。类似于:xml,json,thrift等。但相较于其他序列化,protobuf的主要优点是:简单和快.
通过protocol可将定义的protocol将 .protocol文件转换为:.java文件
集群
-
Master
HBase的管理节点,通常在一个集群中设置一个主Master,一个备Master,主备角色的"仲裁"由ZooKeeper实现。 Master主要职责:
①负责管理所有的RegionServer。
②建表/修改表/删除表等DDL操作请求的服务端执行主体。
③管理所有的数据分片(Region)到RegionServer的分配。
④如果一个RegionServer宕机或进程故障,由Master负责将它原来所负责的Regions转移到其它的RegionServer上继续提供服务。
⑤Master自身也可以作为一个RegionServer提供服务,该能力是可配置的。
什么样的数据适合用HBase来存储?
HBase的数据模型比较简单,数据按照RowKey排序存放,适合HBase存储的数据,可以简单总结如下:
-
以实体为中心的数据
实体可以包括但不限于如下几种:
描述这些实体的,可以有基础属性信息、实体关系(图数据)、所发生的事件(如交易记录、车辆轨迹点)等等。
-
- 自然人/账户/手机号/车辆相关数据
- 用户画像数据(含标签类数据)
- 图数据(关系类数据)
-
以事件为中心的数据
-
- 监控数据
- 时序数据
- 实时位置类数据
- 消息/日志类数据
HBase中的数据为何不直接存放于HDFS之上?
HBase中存储的海量数据记录,通常在几百Bytes到KB级别,如果将这些数据直接存储于HDFS之上,会导致大量的小文件产生,为HDFS的元数据管理节点(NameNode)带来沉重的压力。
文件能否直接存储于HBase里面?
如果是几MB的文件,其实也可以直接存储于HBase里面,我们暂且将这类文件称之为小文件,HBase提供了一个名为MOB的特性来应对这类小文件的存储。但如果是更大的文件,强烈不建议用HBase来存储
schemal设置
-
NameSpace设置
-
Column Family的数量
-
每一个Column Family中所关联的一些关键配置:
-
Compression:HBase当前可以支持Snappy,GZ,LZO,LZ4,Bzip2以及ZSTD压缩算法
-
DataBlock Encoding:HBase针对自身的特殊数据模型所做的一种压缩编码
-
BloomFilter:可用来协助快速判断一条记录是否存在
-
TTL:指定数据的过期时间
-
StoragePolicy:指定Column Family的存储策略,可选项有:"ALL_SSD","ONE_SSD","HOT","WARM","COLD","LAZY_PERSIST"
创建表
建表的请求是通过RPC的方式由Client发送到Master
-
RPC接口基于Protocol Buffer定义
-
建表相关的描述参数,也由Protocol Buffer进行定义及序列化
Master侧接收到Client侧的建表请求以后,一些主要操作包括:
-
生成每一个Region的描述信息对象HRegionInfo,这些描述信息包括:Region ID, Region名称,Key范围,表名称等信息。
-
生成每一个Region在HDFS中的文件目录。
-
将HRegionInfo信息写入到记录元数据的hbase:meta表中。
整个过程中,新表的状态也是记录在hbase:meta表中的,而不用再存储在ZooKeeper中。
如果建表执行了一半,Master进程故障,如何处理?这里是由HBase自身提供的一个名为**Procedure(V2)**的框架来保障操作的事务性的,备Master接管服务以后,将会继续完成整个建表操作。
一个被创建成功的表,还可以被执行如下操作:
- Disable 将所有的Region下线,该表暂停读写服务
- Enable 将一个Disable过的表重新Enable,也就是上线所有的Region来正常提供读写服务
- Alter 更改表或列族的描述信息
BlockCache

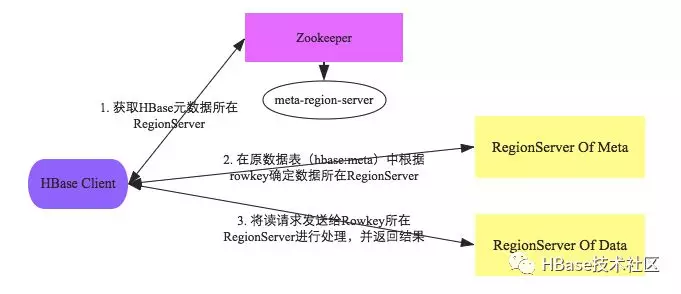
构建Scanner体系
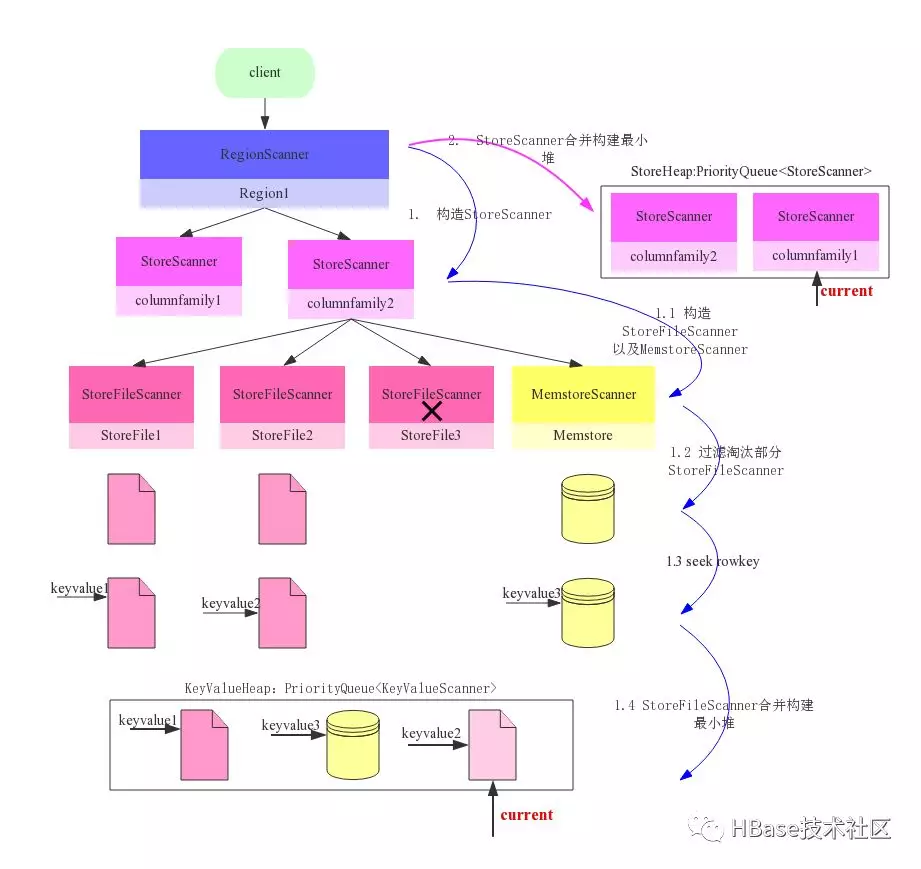
Flush过程